Triton Inference Server는 Nvidia에서 제공하는 오픈소스 모델 서빙 소프트웨어이다.
컨테이너의 형태로 제공되며, 여러 모델들을 로딩하여 API를 제공한다.
다음의 기능들을 제공한다:
- REST / gRPC API
- Prometheus Metrics
- Python, Tensorflow, Pytorch, ONNX, TensorRT, vLLM, FIL 등 다양한 backend
- 여러 모델들을 로딩하며 버저닝
- 모델은 컨테이너의 볼륨을 마운트하거나 클라우드 오브젝트 및 호환 스토리지 이용 가능
- liveness, readines probe
- kserve와 연동가능
🍰 내부 구조
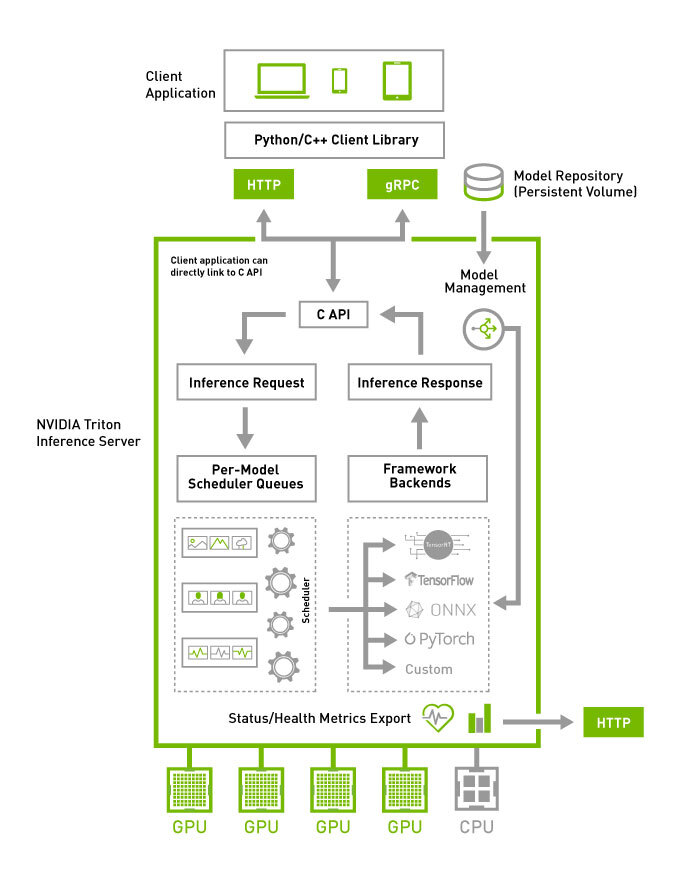
컨테이너 안에는 지원하는 모든 벡엔드들이 들어있고, 모델 레포지토리로부터 모델들을 로딩하며 실제 필요한 벡엔드만 로딩한다.
C API를 통해서 HTTP/gRPC API가 제공된다.
각 요청들은 스케줄러에 의해 적절히 배치된다.
이후, 프레임워크 벡엔드들에서 요청이 처리된다.
각 벡엔드들은 C++ shared library(.so)로 구현되어 있으며, 동적으로 로딩될 수 있다.
메트릭 등은 HTTP API로 제공된다.
🐋 Tritonserver 컨테이너
Tritonserver의 컨테이너 이미지 형식은 nvcr.io/nvidia/triotnserver:<yy.mm>-py3을 따른다.
매월 새로운 릴리스가 나온다.
시작 command는 tritonserver --model-repository=/models이다.
모델 저장소는 보통 /models로 시작하며, 볼륨을 줄때 모델 레포지토리 폴더를 마운트해준다.
또는 오브젝트 스토리지를 이용할 수 있다.
모델 레포지토리의 폴더 구조는 아래와 같다.
이후 글에서 폴더 구조에 대해 더 자세히 알아볼 것이다.
아래는 Pytorch backend의 예시이다.
1
2
3
4
5
6
7
8
|
model_repository
|
+-- resnet50 // 모델 이름
|
+-- config.pbtxt // 필수 configuration file
+-- 1 // 모델 버전
|
+-- model.pt // 모델 파일(torchscript)
|
예시 시작은 아래와 같다. model_repository에 아래 형식처럼 구조를 가져야 한다:
1
|
docker run --rm -p8000:8000 -p8001:8001 -p8002:8002 -v/full/path/to/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:<xx.yy>-py3 tritonserver --model-repository=/models
|
Kubernetes 에서 YAML로 선언할 때에는 아래의 예시가 있다:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
|
# https://kubernetes.io/docs/concepts/workloads/controllers/deployment/
apiVersion: apps/v1
kind: Deployment
metadata:
name: triton-inference-server
namespace: triton
labels:
app: triton-inference-server
spec:
selector:
matchLabels:
app: triton-inference-server
replicas: 1
strategy:
rollingUpdate: # GPU가 한 장일때는 이와 같이 작성 -> 다운타임 존재
maxSurge: 0
maxUnavailable: 1
type: RollingUpdate
template:
metadata:
annotations:
kubectl.kubernetes.io/default-container: triton-inference-server
labels:
app: triton-inference-server
spec:
containers:
- name: triton-inference-server
image: nvcr.io/nvidia/tritonserver:25.09-py3 # YY-MM
imagePullPolicy: IfNotPresent
args:
- tritonserver
- --model-repository=/models
- --strict-model-config=false
- --log-verbose=1
- --disable-auto-complete-config # config.pbtxt 자동생성 비활성화
ports:
- containerPort: 8000 # http
name: http
- containerPort: 8001 # grpc
name: grpc
- containerPort: 8002 # prometheus
name: prometheus
resources:
requests:
cpu: "2"
memory: 2Gi
limits:
cpu: "4"
memory: 4Gi
nvidia.com/gpu: 1 # GPU 한 장
startupProbe:
httpGet:
path: /v2/health/ready
port: 8000
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 10
periodSeconds: 10
livenessProbe:
httpGet:
path: /v2/health/live
port: 8000
timeoutSeconds: 2
failureThreshold: 5
periodSeconds: 10
readinessProbe:
httpGet:
path: /v2/health/ready
port: 8000
timeoutSeconds: 2
successThreshold: 1
failureThreshold: 5
periodSeconds: 10
volumeMounts:
- name: triton-models
mountPath: /models
volumes:
- name: triton-models
persistentVolumeClaim:
claimName: triton-models-pvc
restartPolicy: Always
---
|